Topics for today
- Semantic HTML and why it matters
- The DOM tree
- HTML interactivity and UX concerns
- Reactivity
em element represents stress emphasis of its contents,
while the i element represents text that is set off from the normal prose, such a foreign word, fictional character thoughts, or when the text refers to the definition of a word instead of representing its semantic meaning.
cite.
span carries no semantic meaning.
tabindex attribute removes the element from the tabbing order.
Avoid unless you really know what you're doing.tabindex values greater than 0, as they override the natural source order, which is maintenance nightmare.<input type="text" autofocus>
</div>
</div>
</div>
</ul>
</nav>
</header>
</div>
</div>
</div>
</article>
</section>
</main>
</div>
</div>
</div>
</article>
</section>
</aside>
article or li?
<li>
HTML elements are <strong>objects</strong>,
with a hierarchy called
<em><abbr title="Document Object Model">DOM</abbr>
tree</em>
</li>
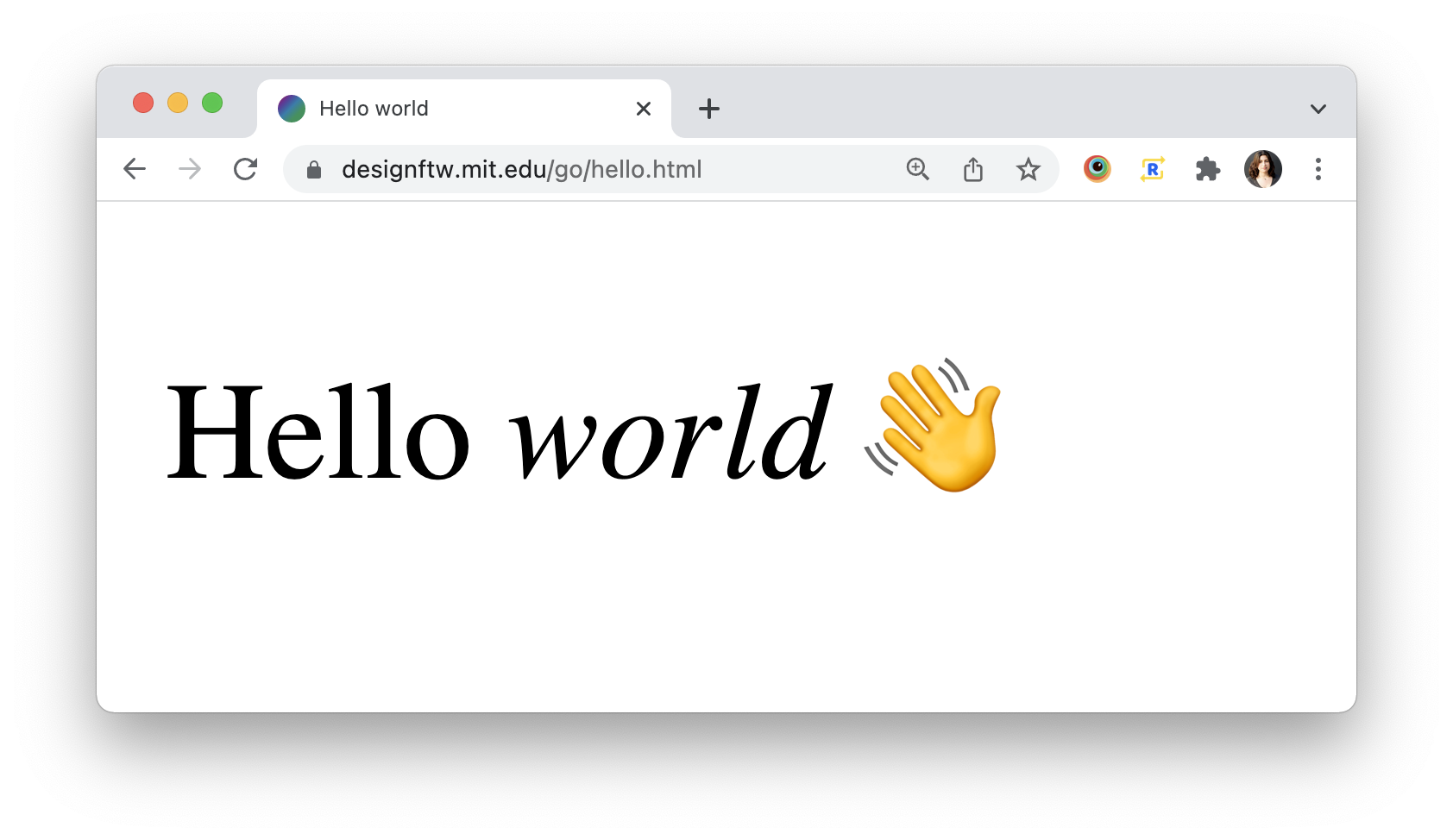
<!DOCTYPE html>
<title>Hello world</title>
<p>Hello <em>world</em> 👋
<!DOCTYPE html>
<html>
<head><title>Hello world</title></head>
<body><p>Hello <em>world</em> 👋</p></body>
</html>
Document:
This is the root node, and does not correspond to any HTML element.HTMLElement:
Every HTML element, such as html, body, or em
is of this type. Usually, they merely inherit from HTMLElement,
and are an instance of a more specific type such as
HTMLHtmlElement,
HTMLBodyElement and so on.Text:
Text nodes, such as "Hello ", "world", and "!" in our example.
These never contain any other element, they are always leaves.
Comment:
HTML comments (<!-- like this -->) are represented by objects of this type.
button element creates buttons.form elements.action attribute of form elements controls which file will receive the submission. By default it's the current file.name attribute.target="_blank" works here too, to submit the form in a new tab<input type="text" placeholder="YYYY-MM-DD">
<input type="number" name="day">
<select name="month">
<option>Jan</option>
<option>Feb</option>...
</select>
<input type="text" name="year">
<input type="number" name="day">
<select name="month">
<option>Jan</option>
<option>Feb</option>
<option>Mar</option>
<option>Apr</option>
<option>May</option>
<option>Jun</option>
<option>Jul</option>
<option>Aug</option>
<option>Sep</option>
<option>Oct</option>
<option>Nov</option>
<option>Dec</option>
</select>
<input type="text" name="year">
<style>input {width: 4em }</style>
<input type="date" />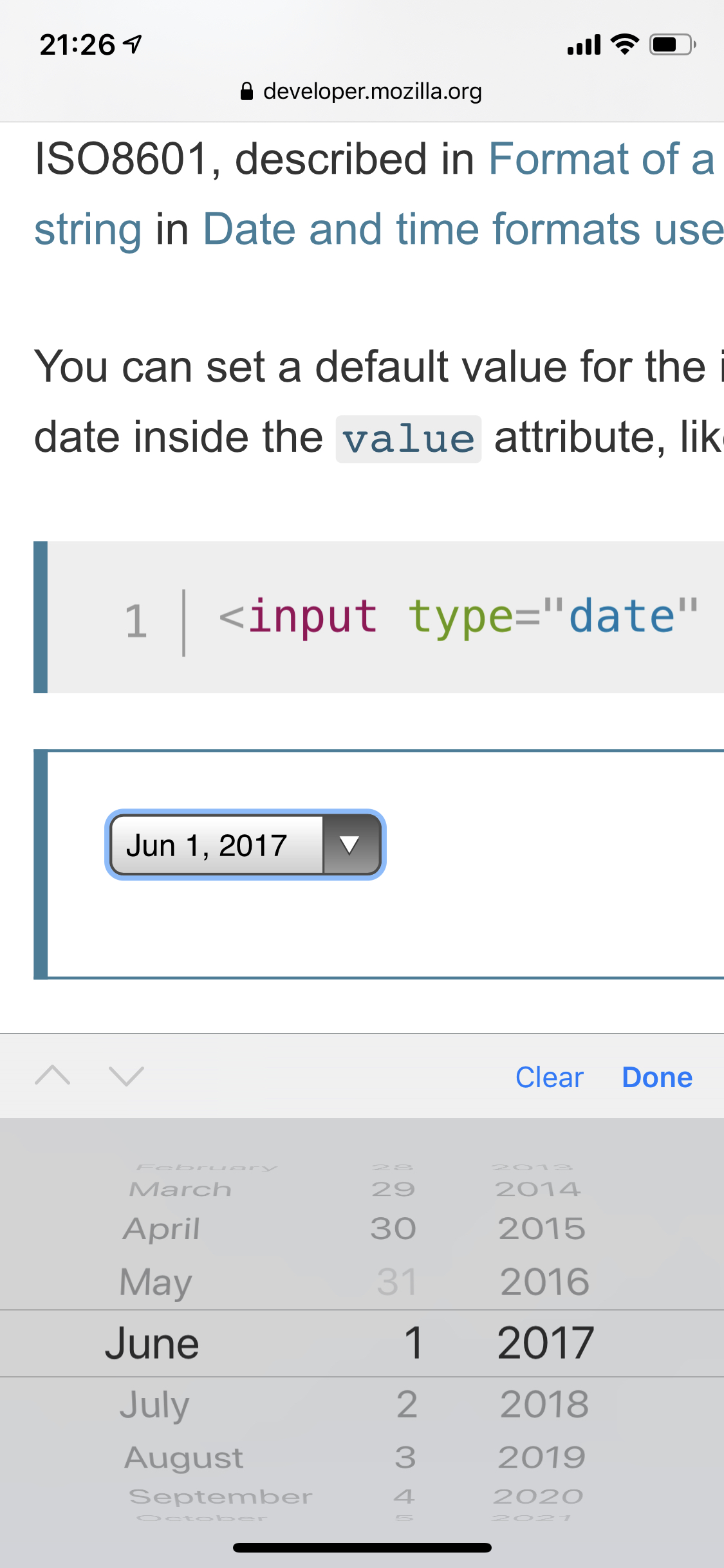
<input type="text">
<input type="email">
<label><input type="radio" name="letter"> A</label>
<label><input type="radio" name="letter"> B</label>
<select name="letter">
<option>A</option>
<option>B</option>...
</select>
<input list="letters" />
<datalist id="letters">
<option>A</option>
<option>B</option>...
</datalist>
Depending on the number of options, different form controls are more appropriate for usability:
<select> menus are ideal<select> menus becomes longer than typing the first few characters.
In those cases, use <input> with <datalist for autocomplete)
<article class="story">
<img src="https://..." alt="...">
<h3>Title</h1>
<p>Content</p>
<a class="read-more" href="...">Read more</a>
{% for story in stories %}
<article class="story">
<img src="{{ story.image }}" alt="{{ story.imageDescription }}">
<h3>{{ story.title }}</h1>
<p>{{ story.content }}</p>
<a class="read-more" href="{{ story.url }}">Read more</a>
</article>
{% endfor %}
let a = 1;
let b = 2;
let sum = a + b; // 3
a = 3;
console.log(sum); // still 3
button.addEventListener("mouseenter", function() {
button.style.boxShadow = "0 0 5px gold";
});
button.addEventListener("mouseleave", function() {
button.style.boxShadow = "";
});
button:hover {
box-shadow: 0 0 5px gold;
}
{
"name": "Lea",
"age": 37,
"numbers": [1, 1, 2, "three"],
"unique-numbers": new Set([1, 1, 2, 3])[1, 2, 3],
"nested": {
"visible": true,
"missing": null
},
}
<title>
<nextid>
<a>
<isindex>
<plaintext>
<listing>
<p>
<h1>
<h2>
<h3>
<h4>
<h5>
<h6>
<address>
<dl>
<dt>
<dd>
<ul>
<li>
reserved for future use.
Web apps with HTML?
Try Mavo out
or just visit play.mavo.io and start coding!