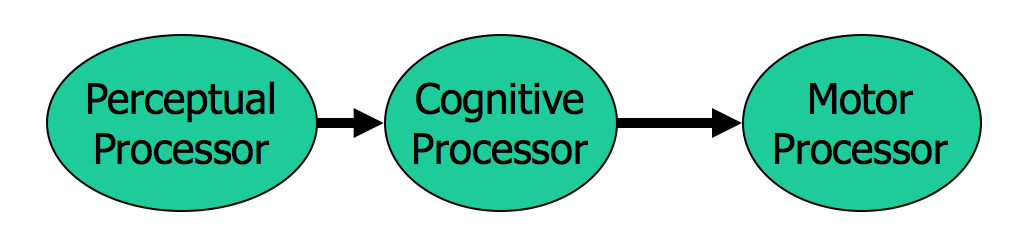
Examples
Internet Explorer
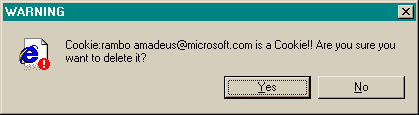
This message used to appear when you tried to delete the contents of your Internet Explorer cache from inside Windows Explorer (i.e., you browse to the cache directory, select a file containing one of IE’s browser cookies, and delete it).
Put aside the fact that the message is almost tautological (“Cookie… is a Cookie”) and overexcited (“!!”).
Does it give the user enough information to make a decision?
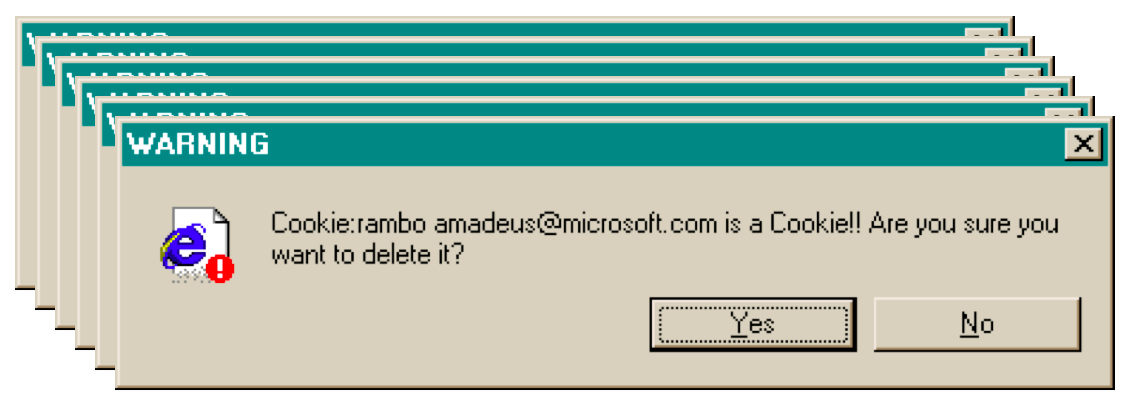
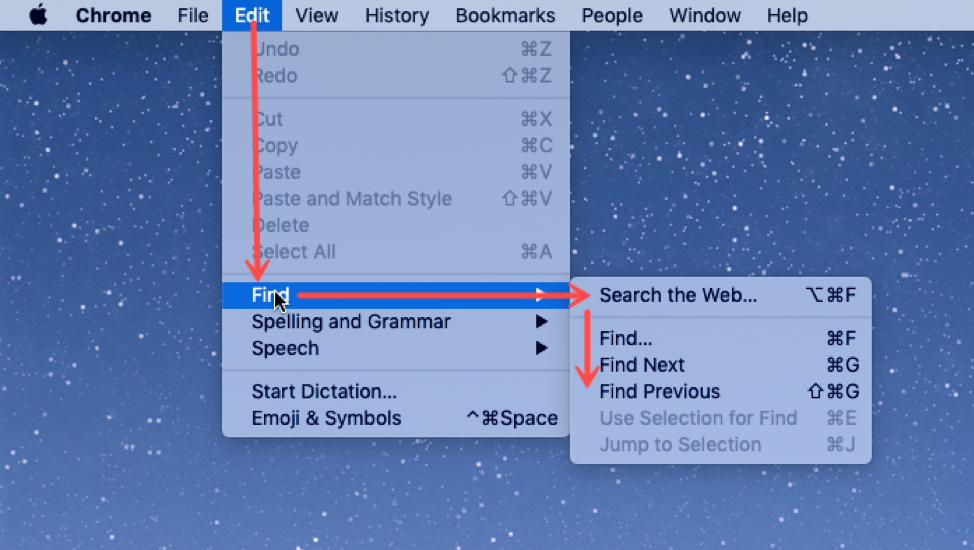
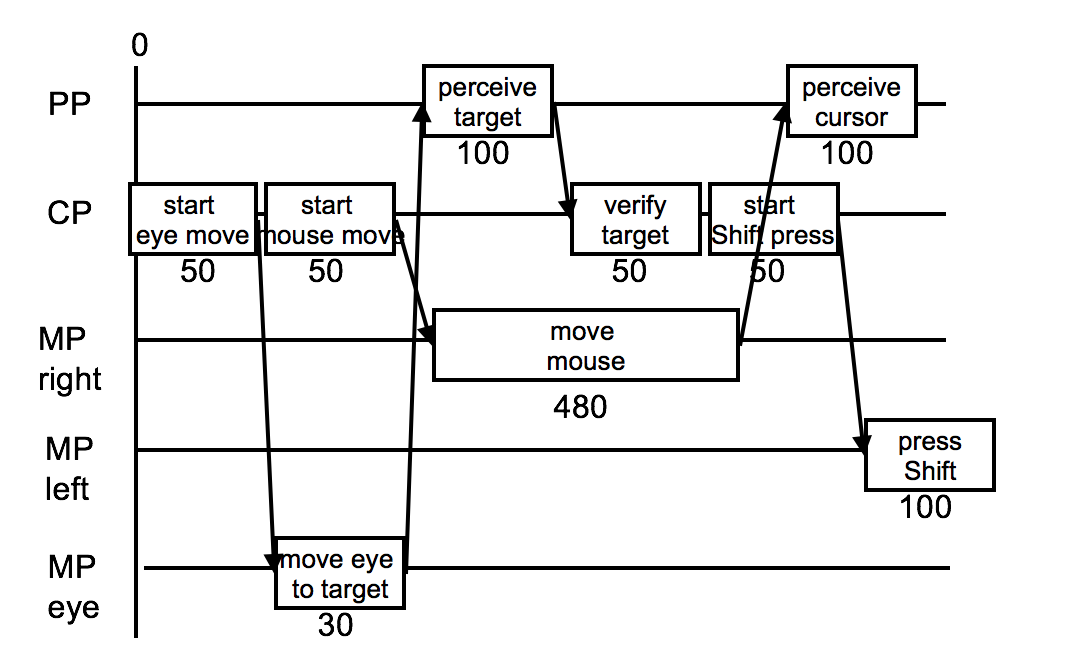
Suppose you selected all your cookie files and tried to delete them all in one go. You get one dialog for every cookie you tried to delete! What button is missing from this dialog?
Microsoft Publishing Wizard
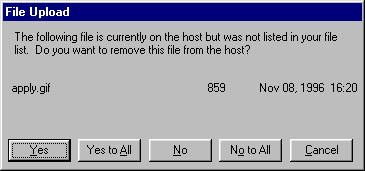
One way to fix the too-many-questions problem is Yes To All and No To All buttons, which short-circuit the rest of the questions by giving a blanket answer. That’s a helpful shortcut, which improves efficiency, but this example shows that it’s not a panacea.
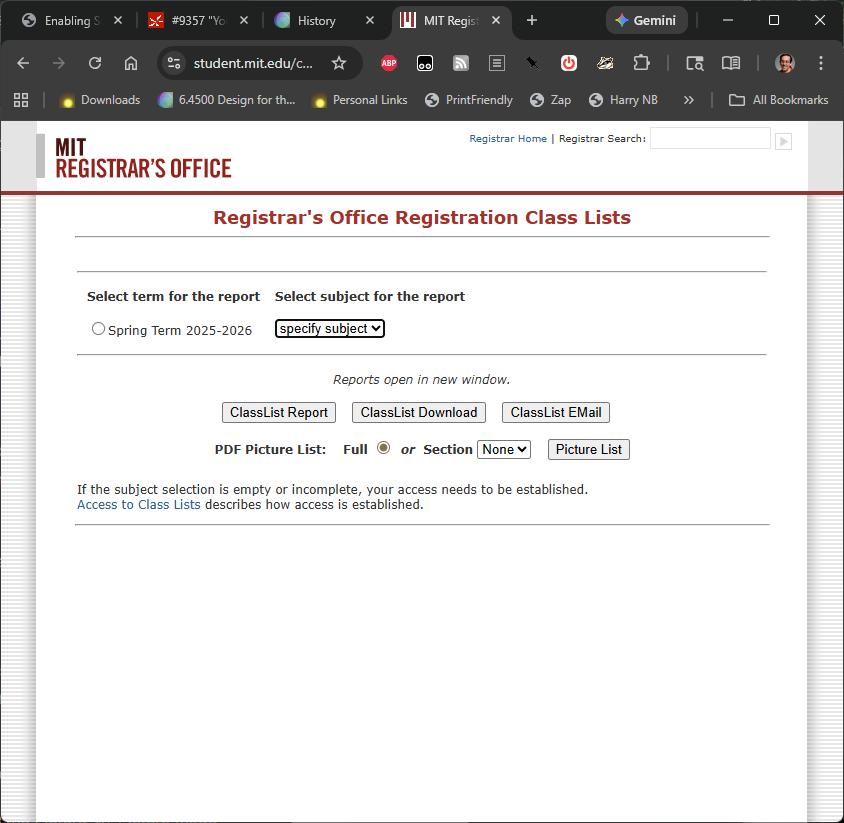
This dialog is from Microsoft’s Web Publishing Wizard, which uploads local files to a remote web site. Since the usual mode of operation in web publishing is to develop a complete copy of the web site locally, and then upload it to the web server all at once, the wizard suggests deleting files on the host that don’t appear in the local files, since they may be orphans in the new version of the web site.
But what if you know there’s a file on the host that you don’t want to delete? What would you have to do?
Eclipse
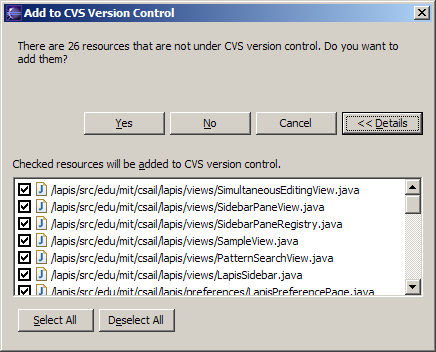
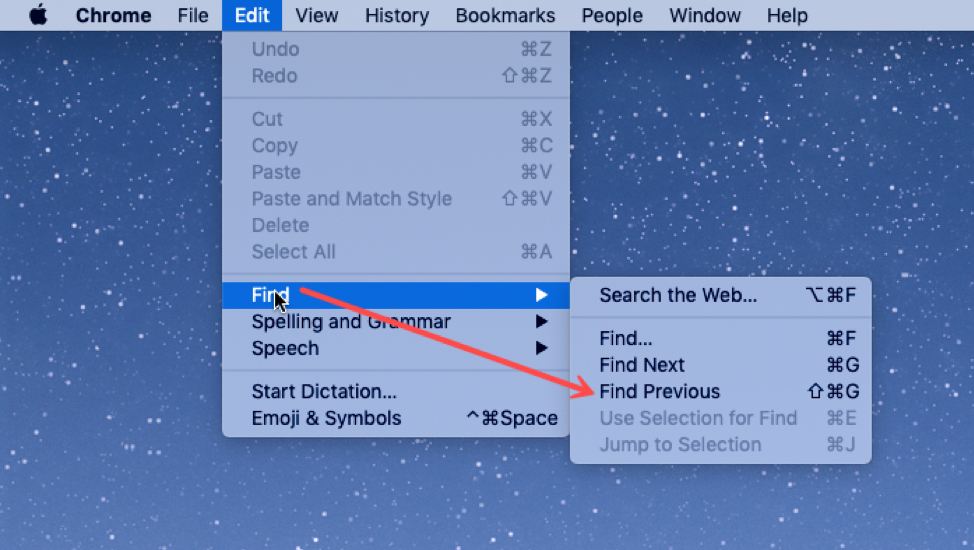
If your interface has a potentially large number of related questions to ask the user, it’s much better to aggregate them into a single dialog. Provide a list of the files, and ask the user to select which ones should be deleted. Select All and Unselect All buttons would serve the role of Yes to All and No to All.
Note that Select All and Unselect All are valuable optimizations for the common cases, where you want to delete (almost) everything or (almost) nothing. But it's still possible to do the uncommon case by looking carefully at each individual checkbox.
Here’s an example of how to do it right, found in Eclipse. If there’s anything to criticize in Eclipse’s dialog box, it might be the fact that it initially doesn’t show the filenames, just their count – you have to press Details to see the whole dialog box. Simply knowing the number of files not under version control is rarely enough information to decide whether you want to say yes or no, so most users are likely to press Details anyway.